Eleventy - Fetch data from the Github REST API to populate a projects page
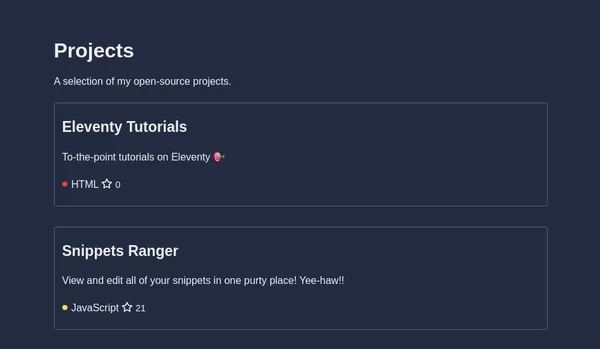
We will create a projects page that is populated with data fetched from the GitHub REST API. The page has a list of project cards like the screenshot below.
We will use the @11ty/eleventy-fetch plugin to fetch and cache the data. We will refresh this data every 2 days. You can choose whatever interval you like!
What we want is to provide a list of repositories to feature on the page. We will store the list in a JSON data file in the following format:
[
{
"title": "Eleventy Tutorials",
"repository": "https://github.com/robole/eleventy-tutorials"
},
{
"title": "Snippets Ranger",
"repository": "https://github.com/robole/vscode-snippets-ranger"
}
]The GitHub Rest API - which endpoint do we use?
Ideally, we would be able to make a single request with our list of repos and get back the same list of repos but with more detailed information. Unfortunately, the GitHub REST API does not quite offer this, we have 2 options:
- Use the “list repositories for a user” endpoint which will return a list of all public repositories for a user. It is up to us to search through the response to get the details for each of our repos.
- Use the “Get a repository” endpoint endpoint to request the detailed information for a single repo. We would need to make a request for each repo.
I will go with option 1. It should be quicker to make a single request and do more processing, rather than make multiple requests and do less processing.
To make a GET request for public data, it is not necessary to be an authenticated user. The following curl command will return all of the public repos for the user robole:
curl -L \
-H "Accept: application/vnd.github+json" \
-H "X-GitHub-Api-Version: 2022-11-28" \
--url "https://api.github.com/users/robole/repos?per_page=100" This returns up to 100 repos sorted by full_name in ascending order. Notice I added the per_page query parameter to increase the number of repos returned from the default of 30 to 100.
Here is a excerpt of the response with only the key fields included:
[
{
"html_url": "https://github.com/robole/eleventy-tutorials",
"description": "To-the-point tutorials on Eleventy 🎯",
"stargazers_count": 0,
"language": "HTML"
},
{
"html_url": "https://github.com/robole/vscode-snippets-ranger",
"description": "View and edit all of your snippets in one purty place! Yee-haw!!",
"stargazers_count": 21,
"language": "JavaScript",
}
]If you have more than 100 public repos, then you will need to use pagination to make additional requests. I will not cover the pagination use case in this tutorial.
The rate limit for unauthenticated users is 60 per hour. This is more than adequate for our needs.
The code
This is an outline of the project files focusing only on the files we will cover:
├─ _data/
│ ├─ projects.json
│ ├─ github.js
├─ _includes/
│ ├─ base_layout.njk
├─ index.njk
├─ projects.njk
├─ eleventy.config.js
Let’s go through the files to see how we get the remote data and use it a webpage.
Our project list - projects.json
This is the data file that has an array of the projects we want to feature on our website. This data will be available in our page templates as a projects variable.
[
{
"title": "Eleventy Tutorials",
"repository": "https://github.com/robole/eleventy-tutorials"
},
{
"title": "Snippets Ranger",
"repository": "https://github.com/robole/vscode-snippets-ranger"
},
{
"title": "File Bunny",
"repository": "https://github.com/robole/vscode-file-bunny"
},
{
"title": "Fetching",
"repository": "https://github.com/robole/fetching"
},
{
"title": "Now Showing",
"repository": "https://github.com/robole/now-showing"
}
]
Fetching the data - github.js
This is the data file that will fetch the public repos for an user. This data will be available in our page templates as a github variable.
I use the @11ty/eleventy-fetch plugin to fetch the data from the API and cache the results. The plugin enables you to request the data at a configurable interval to save on network requests on subsequent builds. I chose to fetch the data every 2 days. By default, the data is stored in the .cache folder.
You can provide parameters to the fetch request through the fetchOptions object, the options are the same as node-fetch, which is used under the hood. We provide the required 2 headers for making a request to the “list repositories for a user” GitHub endpoint.
const fetch = require("@11ty/eleventy-fetch");
module.exports = async function () {
let user = "robole";
let url = `https://api.github.com/users/${user}/repos?per_page=100`;
try {
let json = await fetch(url, {
duration: "2d",
type: "json",
fetchOptions: {
headers: {
Accept: "application/vnd.github+jso",
"X-GitHub-Api-Version": "2022-11-28",
},
},
});
return json;
} catch (error) {
console.error(`Fetch failed in github.js. ${error}`);
}
};You should be careful that you do not store sensitive data in the cache folder and check it into the git repository. We are just requesting public data, so we can do it without any risk. Having the cache folder allows us to reuse the data for each build.
If you do not want to check the cache folder into your git repository, some hosts let you persist a cache folder between builds. For example, Netlify has the netlify-plugin-cache package for this purpose.
Create a find_repo filter to find the repo by its URL - eleventy.config.js
We will create a filter to find a GitHub repo by its URL in our remote data. This will make our projects.njk template cleaner. It is the html_url field in the response that we will inspect.
module.exports = function (config) {
config.addFilter("find_repo", (array, url) => {
let result = array.find((item) => item.html_url === url);
return result;
});
return {
templateFormats: ["njk", "md"],
};
};
Doing this in JavaScript is more efficient because we can use the find() array function to return the first match and look no further. In Nunjucks, we are limited to using a for loop and would have to loop through the entire array of repos since there is no break statement available in Nunjucks.
Our projects page - projects.njk
Our projects.njk template will become our /projects/index.html page. We have access to the projects variable to list our featured projects. We want to loop through this array and show each project as a project card. The project card is wrapped in a link pointing to the GitHub repository.
We use the find_repo filter to get the remote repo instance for each project contained in our github variable. We use the fields: description, language, and stargazers_count to populate our card.
---
layout: base_layout.njk
title: Projects
description: "This is a collection of projects that are hosted on GitHub."
---
<h1>{{ title }}</h1>
<p>A selection of my open-source projects.</p>
<section class="projects">
{% for project in projects %}
<a href="{{ project.repository }}" target="_blank">
<div class="project">
<h3>{{ project.title }}</h3>
{% set repo = github | find_repo(project.repository) %}
<p>{{ repo.description }}</p>
<span class="language repo-{{ repo.language | lower }}">{{ repo.language }}</span>
<span class="stars">
<svg aria-label="stars" viewBox="0 0 16 16"><!--omitted--></svg>
<span class="count">{{ repo.stargazers_count }}</span>
</span>
</div>
</a>
{% endfor %}
</section>
Source code
You will find the code in the github-projects subfolder of the https://github.com/robole/eleventy-tutorials repo.
Did you enjoy this tutorial? If you did, could you give the repo a star to let me know please? 🌟🫶
Conclusion
Fetching remote data and using it to build prerendered pages is powerful. I like this particular use case because it ensures that I do not forget to update the description for my repos on GitHub. I do not need to duplicate data on my own website when I want to share information on some of my projects.
Using the eleventy plugin @11ty/eleventy-fetch, we can fetch and use remote data with minimal code. It is done efficiently by caching results and only makes requests when we want to refresh the data. It has such a minor impact on build times, you feel like you are using local data most of the time.
If you want to see a variation of this in the wild, you can visit my projects page!