How I fixed the feed on my website
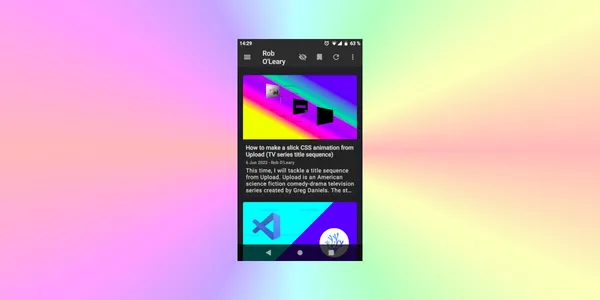
I was trying out some news readers on Linux recently, and I used my own feed as the test input. I noticed that my feed was a bit odd looking in one reader.
It reminded that I had a note to review my feed from ages ago, but it never made it to the top of the list! I have yet to arrive at a version one of my website, so it is a related casualty! Other priorities! ➡️⬇️😅
For whatever reason at the time, I had rushed through making it. I remember that I made it a RSS feed at first, then I switched to Atom. I must have gotten a bit bored along the way. Once it looked fine in one reader, I left it and I added a note to review it later! And later became much, much later i.e. now!
I knew that I needed to review what I was putting into the title and content fields. Also, I wanted to have the cover image of my post as the featured image for the item in the news reader. Most news readers leave it blank, or select an image from the article.
Creating a valid feed
I started by using the W3C validation service to check my feed. It gave me a list of issues.
Nearly all of the issues were related to the content field.
I looked at the Atom spec, it says the following:
<title>,<summary>,<content>, and<rights>contain human-readable text, usually in small quantities. Thetypeattribute determines how this information is encoded (default=“text”)If
type="text", then this element contains plain text with no entity escaped html.
<title type="text">AT&T bought by SBC!</title>If
type="html", then this element contains entity escaped html.
<title type="html">AT&amp;T bought &lt;b&gt;by SBC&lt;/b&gt;!</title>
The important part is the final bit. Even though, you can specify with the type attribute that the content of these fields is HTML, Atom does not like actual HTML elements in there. Notice the &lt; in the examples?
What is that all about? 🤨
XML has its basic syntactical constraints, and Atom has an additional set of constraints set in its schema. Together they determine what is acceptable in the document. This is what the validator uses as its “ruleset”. Since HTML elements are considered invalid in the content field, we must find a way for it to be treated as text.
To be seen as normal text by the parser, we can change the reserved characters to HTML entities. This is what the weird bits of text are. A HTML entity is in the form of &entity_name;.
For example, we change angled brackets into HTML entities, so they are not seen as elements. An opening angled bracket becomes <, and the closing angled bracket becomes >.
The result I want for content would be like this:
<content type="html">
<img src="https://www.roboleary.net/assets/img/blog/2022-06-06-how-to-make-a-slick-css-animation-upload-title-sequence/cover.jpg" alt="cover image" />
<p>This time, I will tackle a title sequence from <a href="https://en.wikipedia.org/wiki/Upload_(TV_series)">Upload</a>.</p>
<p>Upload is an American science fiction comedy-drama television series created by Greg Daniels. The story takes place in 2033, when humans can “upload” themselves into a virtual afterlife of their choosing. When a programmer Nathan Brown dies prematurely, he is uploaded to the luxury Lakeview facility, but then finds himself under the thumb of his possessive, still-living girlfriend Ingrid who has paid for him to be there.</p>
</content>The misleading thing is when you look at a feed in the browser. The same field looks like this:

The browser renders the HTML entities so that it looks like HTML. However, notice that the inner content of the field is not syntax-highlighted like the XML element. This is the hint that it is not treated as markup. It can be easy to miss this fact, and be confused by the output.
Another way to do this is wrap our actual HTML in a CDATA section. This is a way of telling the parser that this data should be considered as text. I have not tested this in readers, so I cannot comment how they respond to it exactly, but I have seen it in other feeds!
I use a liquid template in Jekyll to generate my feed. I added some of the builtin filter functions to strip excess whitespace (strip) and to escape the characters (xml_escape) to be XML-compliant.
<content type="html">
{{ post.content | strip | xml_escape }}
</content>I also added similar filtering to the title. XML differs from HTML in that if it encounters an error, then it stops parsing. Therefore, if there is a single parsing error in your document, the whole document is broken. So better to be safe than sorry!
{% assign post_title = post.title | strip_html | normalize_whitespace | xml_escape %}
<title type="html">{{ post_title }}</title>And this did the trick for me. 🎉
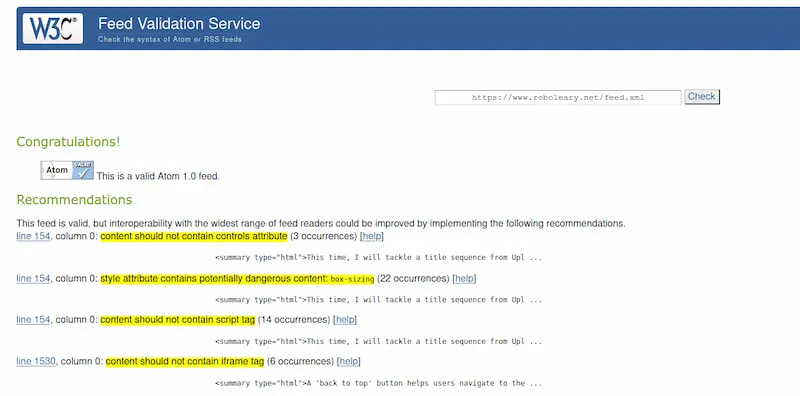
There are still recommendations that usually revolve around not include interactive content such as script and iframe, but that is something I want to keep.
Fixing the featured image
I want to have a featured image for each article in the feed. In posts that I write in markdown, the cover image is not added inline markdown, so it does not make into the post.content variable of Jekyll.
In the Atom spec, there is not a separate field for this.
On Stackoverflow, for the question Displaying images in atom feed, the accepted answer is to add the image as the very first inside the content field. They use a CDATA section to tell the parser that this should be treated like text.
I did the character escaping myself as I needed to include some dynamic data. I wanted to ensure that I get an absolute URL for the image:
<content type="html">
{% if post_image %}
{% unless post_image contains "://" %}
{% assign post_image = post_image | absolute_url %}
{% endunless %}
alt="cover image">
{% endif %}
<!-- post content here -->
</content>This is what it looks in the Feeder Android app:
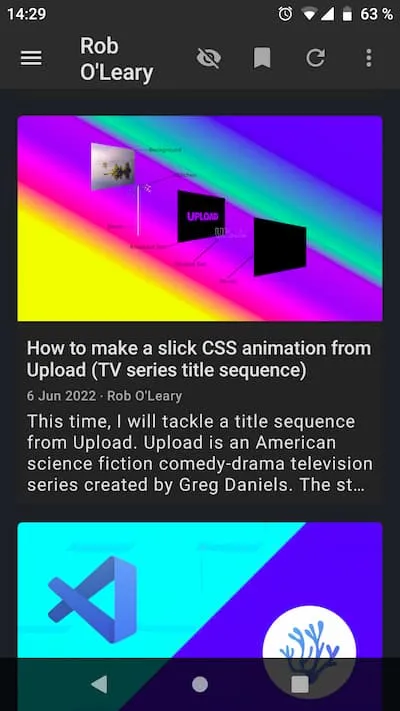
It looks good! 🌟
Creating a better ID for each article
One way that readers know that you published something new is to check the id field of the entry, along with the dates involved.
It is recommended that you do not use the URL for this field because you can change the title of the post or the filename, which may change the id and trigger the entry being downloaded by the reader as a new post. It is better to create an unique id tied to something else.
I used this old article as inspiration, How to make a good ID in Atom.
Now, my ID is in the format of tag:<domain_name>,<post_date as 'yyyy-mm-dd'>:/blog/<post_date in seconds from unix epoch>. So the id for my previous post is <id>tag:roboleary.net,2022-06-13:/blog/1655074800</id>.
To ensure that the seconds since unix epoch does not vary depending on what time zone I am in. I set the timezone for the Jekyll generator in the configuration file.
The limitation of this approach is that I cannot post more than one article per day without there being a clash of IDs. This is because I cannot specify the hour that I pubish the article on. I am fine with this.
Adding some extra fields to improve metadata
I reviewed the other fields to see if there was any missing metadata that might be worth adding in.
I noticed that there was no description for my feed, so I added subtitle.
This is what the feed overview looks like now in Liferea reader:

The content of subtitle is featured at the bottom.
Wrapping up
When working with XML-based formats, you need to be careful. XML is less forgiving than HTML. To create a feed is relatively straightforward as it is a well worn path. There are plenty of plugins for static site generators, but you still need to be careful if you are copying some configuration from somewhere else, or you are not familiar with XML, or in my case if you rush through it! This is a habit I should avoid!
If you having issues with your Atom feed, this may help. You can look at my feed as an example.
Also, apologies to anyone who is subscribed to my feed! 😊
You may notice that some items have been duplicated because of the changes I made. If that is the case and it annoys, the simplest fix is to remove the feed, clear the cache, and then add it back again.
If there is still an issue, please let me know!
Thanks for reading!